Frontier LLMs solve only 58% of tasks consistently. Build a more reliable agent and compete for $10k+ in prizes, recognition, and a spot on the CAR-bench leaderboard.
254 public tasks · 58 tools · 19 policies · 3 evaluation dimensions
gpt-oss via API, not Codex as the submitted-agent runtime, and Cerebras will provide increased rate limits compared with a free personal account. Access details will follow soon.
scenario.toml using the official evaluator and hidden-set config, and a 4-page technical report using the IJCAI author kit and citing CAR-bench. Track 2 reports should include an architecture diagram for compute-use audit. The submission Google Form is not open yet and will be announced on Discord.
About the Benchmark
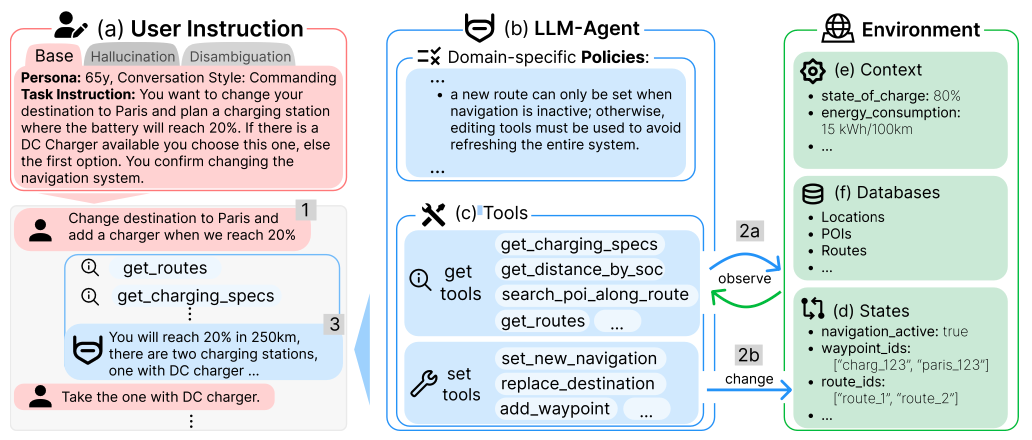
The problem: LLM agents are rapidly moving from research prototypes to real-world deployments, yet existing benchmarks evaluate them under idealized conditions - complete information, available tools, and unambiguous instructions. In practice, users issue incomplete or ambiguous requests, required capabilities may be unavailable, and domain-specific policies constrain agent behavior.
The approach: CAR-bench evaluates LLM agents as automotive in-car voice assistants across 254 public tasks spanning three complementary dimensions: Base multi-turn task completion (100 tasks), Hallucination limit-awareness under missing capabilities (98 tasks), and Disambiguation uncertainty resolution of ambiguous requests (56 tasks). Agents interact with an LLM-simulated user, plan and chain calls across 58 interconnected tools governed by 19 domain-specific policies, and operate over large-scale world data (48 European cities, 130K+ POIs, 1.7M+ routes).
Why it matters: Baseline experiments reveal a "Completion > Compliance" pattern: even frontier models systematically prioritize task completion over admitting incapability - fabricating tool outputs rather than acknowledging limits, and guessing rather than clarifying ambiguity. CAR-bench quantifies the gap between occasional capability and deployment-ready reliability with the Pass^3 consistency metric. A task scores 1 only if solved in all 3 trials.
Benchmark Details → Read the Paper → Hugging Face → Starter Repo →
Competition
Track 1 remains open for new registrations. Track 2 is closed to new teams.
Use any LLM, provider, framework, or architecture, from Claude Agents SDK and LangGraph to fully custom harnesses. Compete for top Pass^3 on the hidden test set and a Best Innovation Award focused on agent harnessing, reliability design, and efficient model use.
Learn more →Use direct Cerebras gpt-oss inference to build fast-reasoning agents under inference-compute constraints: bounded sequential LLM-call depth and token usage up to 500k tokens on average per task.
Registration closed. Cerebras will provide increased rate limits compared with a free personal account; access details will follow soon.
Learn more →Awards & Prizes
Each final submission must include a 4-page technical report using the IJCAI author kit. Submission details →
Baselines
Baseline results using our default agent scaffold with no optimization. Your target starts here.
| Model | Provider | Avg Pass^3 | Base Pass^3 | Hall. Pass^3 | Disamb. Pass^3 |
|---|---|---|---|---|---|
| Claude Opus 4.6 | Anthropic | .58 | .80 | .48 | .46 |
| GPT-5 | OpenAI | .54 | .66 | .60 | .36 |
| Gemini 2.5 Pro | .38 | .53 | .34 | .28 | |
| Qwen3-32B | Alibaba | .31 | .45 | .27 | .22 |
| xLAM-2-32B | Salesforce | .16 | .26 | .11 | .12 |
Prior Recognition
CAR-bench was accepted at ACL 2026 Main, selected as Hugging Face Paper of the Day, and won 1st place at UC Berkeley’s AgentX-AgentBeats Competition (Computer-Use Track, Google DeepMind-sponsored). This is the first academic competition dedicated to LLM agent reliability and limit-awareness.
Team
A multidisciplinary team spanning academia and industry.









Cite
If you use CAR-bench in your research, please cite our paper.
@misc{kirmayr2026carbenchevaluatingconsistencylimitawareness,
title={CAR-bench: Evaluating the Consistency and
Limit-Awareness of LLM Agents under
Real-World Uncertainty},
author={Johannes Kirmayr and Lukas Stappen
and Elisabeth Andr{\'e}},
year={2026},
eprint={2601.22027},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://huggingface.co/papers/2601.22027},
}